The h-index is the best known author-level metric. Since it was proposed by J.E. Hirsch in 2005, it has gained a lot of popularity amongst researchers while bibliometrics scholars proposed a few variants to account for its weaknesses (e.g., g-index, m-index).
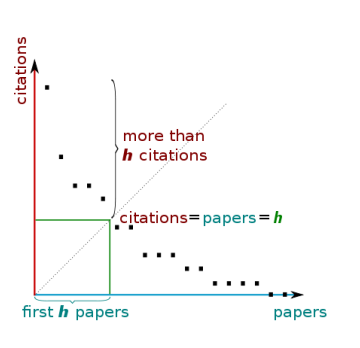
The h-index attempts to measure both the productivity and impact of the published work of a scientist or scholar. The calculation can be summed up as:
A scientist has an index h if h of his/her Np papers has at least h citations each, and the other (Np h) papers have no more than h citations each.
An example of this in practice would be an author having an h-index of 5 because they have 5 publications, each receiving at least 5 citations.

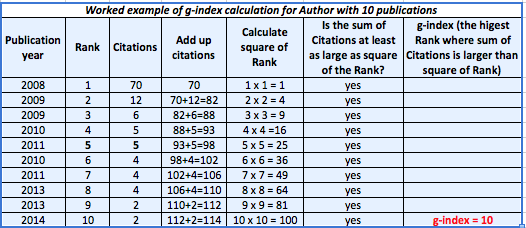
The g-index is a variant of the h-index that, in its calculation, gives credit for the most highly cited papers in a data set.
In the words of Leo Egghe, its inventor: "Highly cited papers are, of course, important for the determination of the value h of the h-index. But once a paper is selected to belong to the top h papers, this paper is not “used” any more in the determination of h, as a variable over time. Indeed, once a paper is selected to the top group, the h-index calculated in subsequent years is not at all influenced by this paper’s received citations further on: even if the paper doubles or triples its number of citations (or even more) the subsequent h-indexes are not influenced by this."
The g-index is always the same as or higher than the h-index.
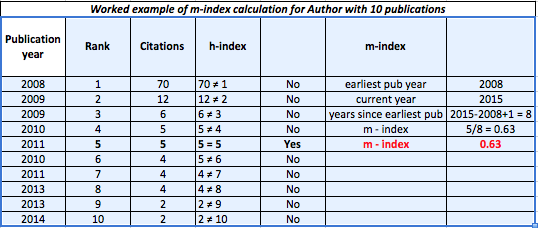
The m-index is another variant of the h-index that displays h-index per year since first publication.
The h-index tends to increase with career length, and m-index can be used in situations where this is a shortcoming, such as comparing researchers within a field but with very different career lengths.
The m-index inherently assumes unbroken research activity since the first publication.